
Apache Sedona (GeoSpark): Using PySpark
GeoPandas replacement for Spark
From head to toe
After struggling through many sites, posts & videos, I wasn’t able to find a good comprehensive article which just does not explain what Apache Sedona (formerly known as GeoSpark) is? But also throw some light on installing and configuring it.
There is a very good documentation provided by Apache on installation & usage but for a person who is new to the Spark environment might have some trouble going through the steps in order to match all the bits and pieces together.
Introduction
If you are dealing with location information (latitude & longitude) in your dataset & have only heard about GeoPandas so far, you would likely know its limitations as well. As amazing as GeoPandas may, when you build applications, projects or ML models, you can’t scale GeoPandas dataframes on big data sets. You need to have a framework which is Spark friendly & functions that can be applied directly on Spark dataframes without converting into Pandas. In my opinion, GeoPandas & Pandas are great to work with, but when you want to scale your application for big data or you want to productionalize your models, you need a framework which is easy to scale with Big Data. For this Spark can be a good choice because of its distributed computing architecture. But the question is, how to perform spatial joins & other functions, when you have one Spark dataframe and the other as the GeoPandas dataframe. No! converting Spark dataframe into pandas is not an option because it won’t work on big data and if you convert GeoPandas into Spark dataframe then how would you perform spatial joins? For this, we have been blessed with Apache Sedona (GeoSpark) to let our worries drain down into gutters.
So without much beating around the bushes, let me take you directly inside the bushes and see how to get started using this amazing framework.
Prerequisite
Spark 3.0.0
Open your terminal and check if you have Spark version 3.0 by typing in the following command
spark-submit --versionIf you don’t have it, you can download Spark from this link & follow these steps in order to install Spark 3.0
Installation
Step 1
First, you need to install Apache Sedona in your Spark environment.
Execute the following command from your terminal to install.
pip install apache-sedonaThis will install following libraries:
- sedona
- pyspark
- shapely
- attrs
Step 2
To make Sedona work properly, you need to download below two jar files
sedona-python-adapter-3.0_2.12–1.0.0-incubating.jar
geotools-wrapper-geotools-24.0.jarYou can get these two jars from the following links.
Step 3
Once jar files downloaded, you have to copy them inside your Spark jar folder. It would be something like,
Windows :
C:/Spark/spark-3.0.2-bin-hadoop2.7/jars/Mac :
/Users/<your mac name>/spark-3.0.2-bin-hadoop2.7/jars/And you are all done!
Let’s see below the usage & how to write applications from what we have configured just now.
Usage
Writing application
At first, as with any other library, we have to import Sedona packages.
from sedona.register import SedonaRegistrator
from sedona.utils import SedonaKryoRegistrator, KryoSerializerNow, it’s time to create a spark session and pass Sedona config while setting up the spark context.
spark = SparkSession.\
builder.\
master("local[*]").\
appName("Sedona App").\
config("spark.serializer", KryoSerializer.getName).\
config("spark.kryo.registrator",
SedonaKryoRegistrator.getName)\
getOrCreate()Using KryoSerializer.getName and SedonaKryoRegistrator.getName class properties to reduce memory impact.
To turn on SedonaSQL function inside pyspark code use SedonaRegistrator.registerAll method on existing pyspark.sql.SparkSession instance ex.
SedonaRegistrator.registerAll(spark)Once done, you have a spark session with Sedona framework activated. You are good to use Sedona functions & perform GeoSpatial joins between two spark dataframes.
Let’s visualize this with an example here.
Example
All SedonaSQL functions (list depends on SedonaSQL version) are available in Python API. For details you can refer to API/SedonaSQL page here.
For this example, we will use SedonaSQL for Spatial Join.
counties = spark.\
read.\
option("delimiter", "|").\
option("header", "true").\
csv("counties.csv") counties.createOrReplaceTempView("county") counties_geom = spark.sql(
"""SELECT county_code,
st_geomFromWKT(geom) as geometry
from county"""
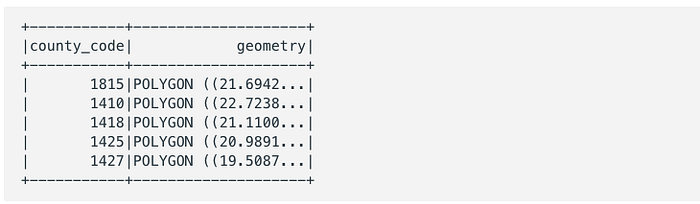
) counties_geom.show(5)
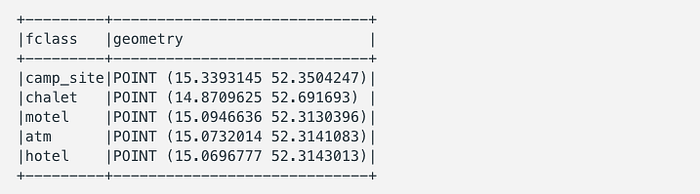
import geopandas as gpd points = gpd.read_file("gis_osm_pois_free_1.shp") points_geom = spark.createDataFrame(
points[["fclass", "geometry"]] ) points_geom.show(5, False)
points_geom.createOrReplaceTempView("pois") counties_geom.createOrReplaceTempView("counties") spatial_join_result = spark.sql(
"""SELECT c.county_code,
p.fclass
FROM pois AS p,
counties AS c
WHERE ST_Intersects(p.geometry, c.geometry)
""" )
And here you go! You did your first geospatial join only using Spark & nothing in Pandas or GeoPandas. This will make your projects & models highly scalable for big data and production ready.
Please write in the comment if you face any trouble while installing it.
